
Over the past few weeks, the release of ChatGPT has garnered reactions of amusement, awe, and even mild, global panic. Many tasks deemed uniquely human—from blogging to holding believable conversations and even passing the bar exam—can now be performed with the push of a button, at scale. As AI and automation continue to advance, the question we’re all asking is how these increasingly advanced models will shape the future of work. Will they replace humans or create new opportunities?
At Cohere, we work with companies of all shapes and sizes—from small startups to large enterprises—to serve customers faster and more efficiently using AI. Recently, a few clients came to us asking how we can expand our use of language models like ChatGPT in customer support. This is something that everyone’s been asking, so let’s dive in!
How do LLMs (large language models) work? Which one is the best?
To understand the origin of ChatGPT’s conversational superpowers, we have to understand how it’s trained. Traditional language models used in NLP (natural language processing), such as the IBM Watson deployment that stunned Jeopardy viewers in 2011, are trained with databases of facts presented in a format that computers can understand. When a question is posed, a specialized computer program searches this database by running traditional graph search and keyword-matching techniques.
This approach works well for certain use cases, and the returned answers tend to be factually accurate (when they can be found). However, considerable time and labor are required to manually process and clean the data, and the resulting models often perform poorly when questions use different words or phrasing.
Newer language models like ChatGPT employ a different approach called unsupervised learning. They are trained directly from raw data collected at vast scales (books, scientific papers, news articles, Twitter posts, etc.) with minimal human effort. These models are not initially trained on facts or any ground truth objectives. Their job, rather, is to predict plausible ways to finish sentences based on the statistics of human language.
With large-scale unsupervised learning, these newer models are much better at processing the complexities of language and performing tasks that they haven’t been explicitly trained on. They can also be fine-tuned to tackle specialized tasks, such as generating legal documents or parsing medical literature. As of December 2022, the best publicly available language models on general natural language benchmarks are OpenAI’s GPT series and Google’s FLAN-T5 and UL2 series, which we use in production at Cohere.
What are LLMs good and bad at?
Think of ChatGPT as an autocomplete feature on your phone keyboard, but much smarter and more compute-hungry. It excels at generating plausible ways to complete a piece of text and performs well on problems where:
- There is no one correct answer (creative applications, summarization)
- There is some tolerance for error (routing, tagging, searching, and other tasks where perfection isn’t required)
- The answer can be easily verified (math, writing code for specific tasks, or human-in-the-loop use cases).
As a result, ChatGPT excels at maintaining fluent conversations. This characteristic is both a blessing and a curse–in order for ChatGPT to hold fluent and natural conversations, it needs to be able to consistently generate plausible responses. However, what’s plausible isn’t necessarily true.
For example, if you ask ChatGPT to "Write a biography for Bloomberg reporter Matt Levine,” it will generate a plausible biography for a financial reporter but with fabricated details. For instance, the school names are completely wrong in the following example:
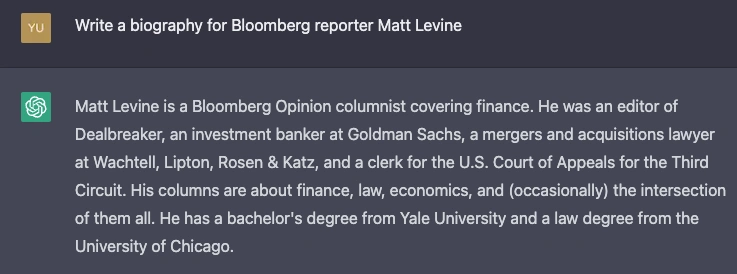
If you ask it to come up with a biography for a less famous person like myself, here’s what you get:

The generated biography is believable, but the details of my gender and actual experience are completely made up.
In summary, LLMs like ChatGPT are good at transforming text, but are bad at retrieving information. As you can imagine, the potential dangers are numerous (especially if the responses sound believable)–imagine a medical chatbot that makes up dosing regimes for drugs, or a tax chatbot that instructs clients to submit fraudulent deductions.
How can LLMs be safely used for customer support?
Despite the limitations, there are numerous opportunities for large language models like ChatGPT in the realm of customer support.
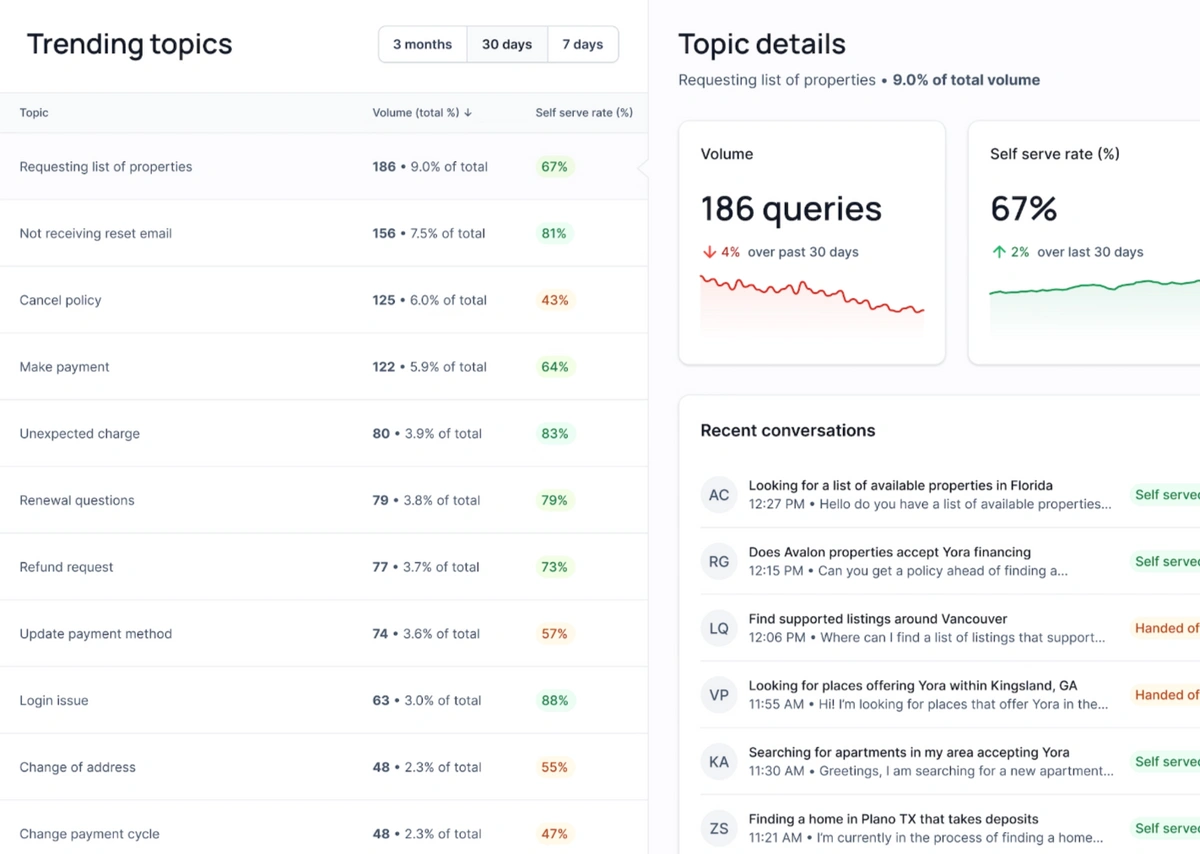
For example, LLMs can be used to compare the meanings of two pieces of text. We use this capability at Cohere to:
- Help clients identify repetitive questions, even if they’re phrased differently or include extraneous details. This allows support and content teams to identify and focus their efforts on the most pressing issues.
- Leverage existing content like help articles and programmable workflows to automatically solve these questions
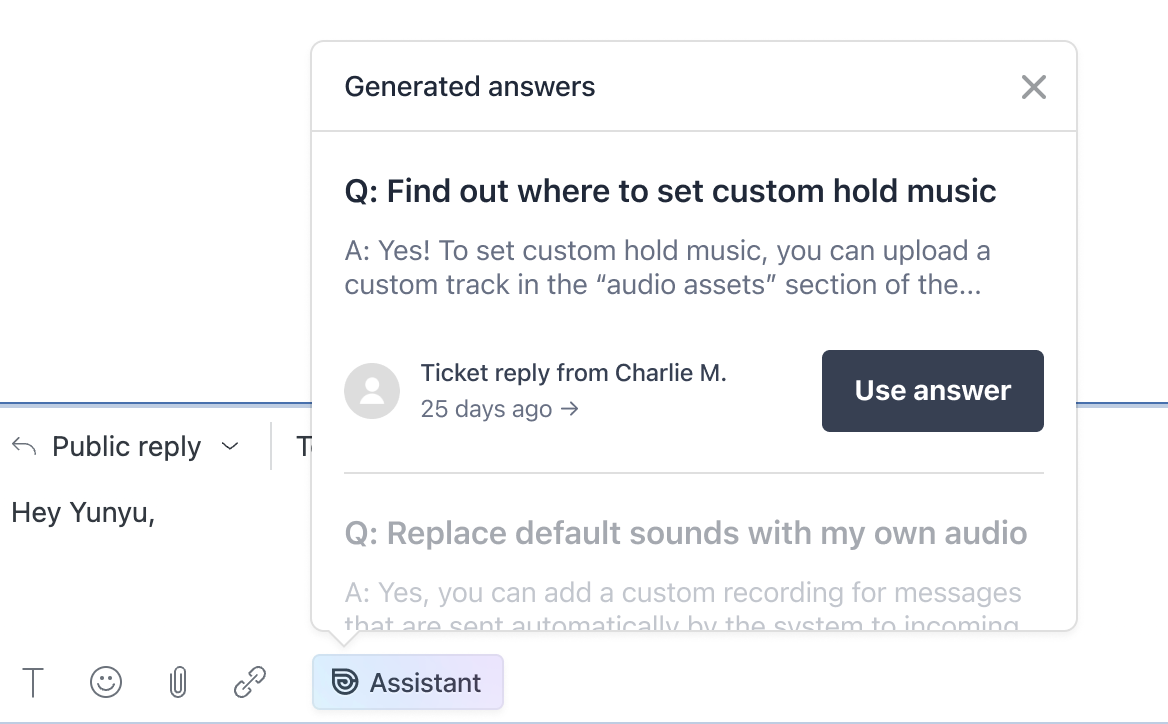
The feature of LLMs that has garnered the most attention, however, is their ability to generate text. Some care is needed to mitigate the risk of surfacing incorrect information to end users. At Cohere, we combine text generation with human review in a few ways to:
- Generate support content by extracting answers from agent responses. For instance, if an agent answers a new question, their response can be turned into help content and used to automatically answer similar questions in the future.
- Help agents draft a large portion of their support responses, saving them time by offering intelligent suggestions that they need only to verify quickly.
By intelligently applying LLM technologies, support teams on the Cohere platform can automatically resolve 30-60% of questions over email and chat while offering world-class human assistance.
How will LLMs evolve in the future?

Although current text generation models have a long way to go before they can be used without human oversight, the progress achieved in recent years has been remarkable. In 2019, the best language models underperformed humans by almost 30% on a popular benchmark of common sense reasoning and question-answering tasks (SuperGLUE). Two years later, Microsoft’s DeBERTA model outperformed humans on the same benchmark by 4%.
We can anticipate similar advances in the coming years as AI models become increasingly competitive with humans. For example, we are already seeing early models that can process images, text, and audio together. These could open the door for truly personalized automation that can gather context and provide resolutions across multiple channels.
In conclusion, LLMs like ChatGPT are powerful tools that are already being used by support teams across the world; however, we must take proper caution when utilizing them in customer-facing scenarios. In the coming years, we can expect to see LLMs grow more powerful and unlock new opportunities across a vast range of tasks.
At Cohere, we’re passionate about helping support teams deploy AI safely and responsibly. If you’re curious to see how these technologies can transform your operations, please reach out to our team.
